Оглавление
Что нужно знать про оформление запросов
Немного теории
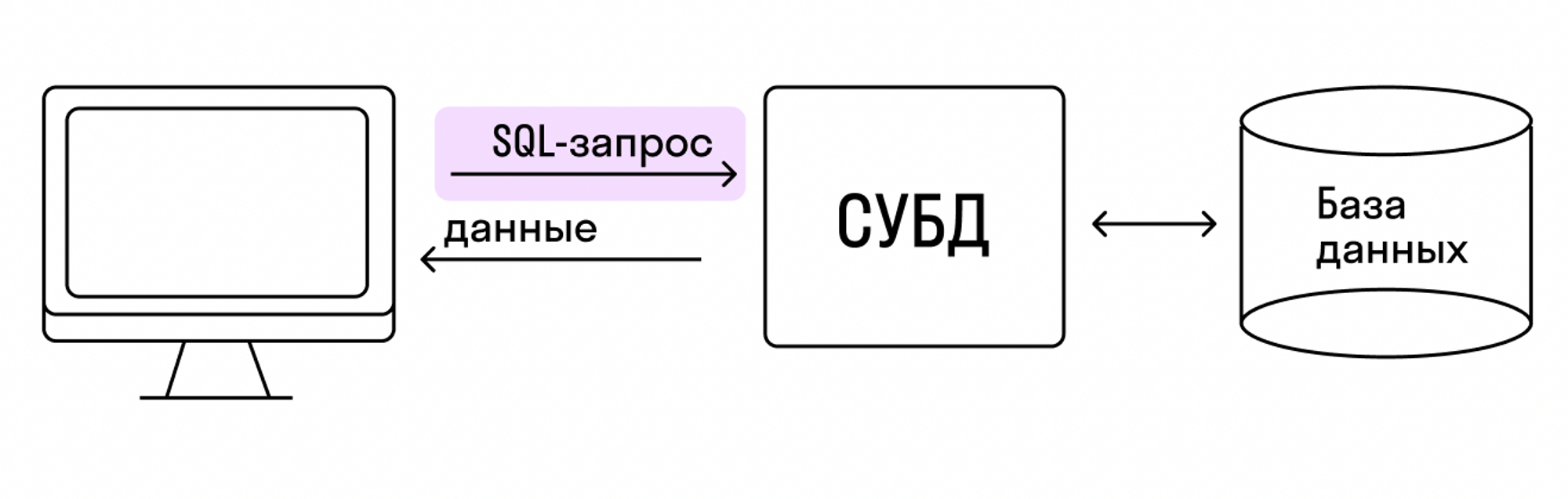
Существуют два вида БД: 1. **Реляционные** базы данных. В них данные хранятся в виде связанных таблиц. 2. **Нереляционные** базы данных. В них данные хранятся иначе. Например, в виде словаря или дерева. Данные в большинстве компаний хранятся в реляционных базах данных в виде связанных между собой таблиц. Обращаться к базе данных с помощью **SQL-запросов** нам позволяет **система управления базами данных — СУБД**.
Как начать работу с SQLite3
con = sqlite3.connect("#name_of_bd") # Подключаемся к БД
cur = con.cursor() # Запускаем курсор, с помощью которого мы будем получать данные из БД
sqlite_query = "ЗДЕСЬ БУДЕТ ТЕКСТ ВАШЕГО ЗАПРОСА"
cur.execute(sqlite_query) # Выполняем запрос с помощью курсора
cur.fetchall() # С помощью этой функции получаем результат запроса в виде списка кортежей
con.close() # После выполнения запросов обязательно закрываем соединение с БД
Простые SQL-запросы
**SQL-запрос** состоит из ключевых слов. На уроке мы изучили **3 ключевых слова:** - SELECT — ключевое слово для извлечения данных. - FROM — ключевое слово для определения таблицы. - WHERE — ключевое слово для фильтрации данных. Чтобы получить все данные из таблицы, достаточно написать:
SELECT * FROM netflix
Если нам нужно получить не все данные, а соответствующие какому-то условию, здесь поможет ключевое слово WHERE:
SELECT title FROM netflix
WHERE type = 'TV Show'
Обратите внимание: так как запрос мы будем писать внутри переменной, важно не запутаться в кавычках. В нашем случае запрос будет выглядеть так:
sqlite_query = "SELECT title FROM netflix WHERE type = 'TV Show'"
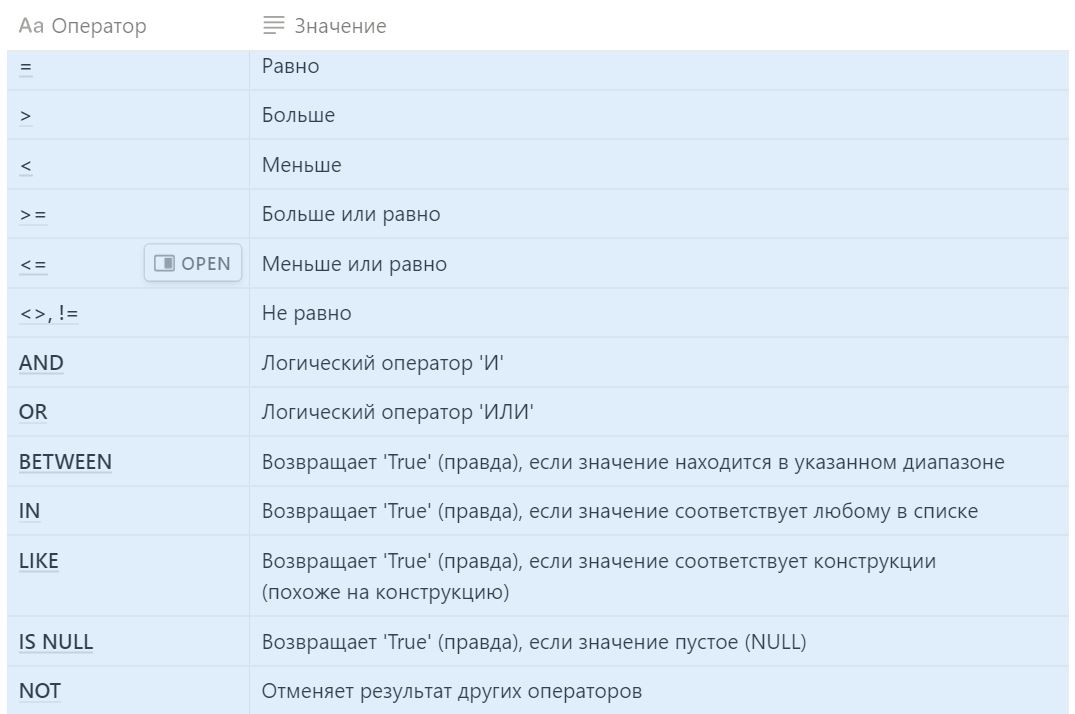
Двойные кавычки — в начале и конце запроса, одинарные — там, где мы ищем строковое значение. Для ключевого слова WHERE существует несколько **операторов** условий.
LIMIT OFFSET
Если нам требуется ограничить вывод данных, можно использовать конструкцию LIMIT ... OFFSET ... - LIMIT — указать, сколько строк выводим - OFFSET — указать, сколько строк пропустить перед выводом. Если отступ не нужен, использовать OFFSET не обязательно.
SELECT * FROM netflix
LIMIT 10 OFFSET 1000
Такой запрос выведет нам строки с 1000 по 1010 из базы данных Netflix.
### Организация приложения
Если вы пишете приложение на flask, работу с базой данных лучше вынести в отельный файл, реализовав каждый отдельный запрос как функцию. Например так
# utils.py
def get_movie_by_id(id):
con = sqlite3.connect(<имя бд>) # Подключаемся к БД
cur = con.cursor() # Запускаем курсор, с помощью которого мы будем получать данные из БД
sqlite_query = "<код запроса>"
result = cur.execute(sqlite_query) # Выполняем запрос с помощью курсора
data = cur.fetchone() # С помощью этой функции получаем результат запроса в виде списка кортежей
con.close() # После выполнения запросов обязательно закрываем соединение с БД
return data[0], data[1]
# app.py
from utils import get_movie_by_id
@app.route("/movies/<movie_id>")
def page_movies(movie_id):
movie = get_movie_by_id(movie_id)
render_template(<шаблон>, movie=movie)
Получение результатов запроса
После того, как запрос выполнен, данные еще нужно вытащить. Это можно делать по одной строке за раз или взять все сразу.
# Вернет одну запись в виде кортежа
cursor.execute(<запрос>)
raw_row = cursor.fetchone()
# Вернет все записи в виде списка кортежей
cursor.execute(<запрос>)
raw_data = cursor.fetchall()
# Вернет названия колонок в виде кортежа
cursor.execute(<запрос>)
column_names = cursor.description
Что нужно знать про оформление запросов
Так как мы пишем с вами запрос в виде переменной типа string, лучше выделять ключевые слова заглавными буквами — так проще будет разобраться, что где находится. Если текст запроса достаточно объемный, лучше разбить его на несколько строк. Как минимум принято делать перенос перед ключевым словом WHERE.
query = "SELECT `title`, `country`, `release_year`" \
"FROM netflix " \
"WHERE title = '1994' " \
"ORDER BY `release_year` " \
"LIMIT 1"
Оглавление
Порядок выполнения SQL-операций
Сортировка данных
Для сортировки данных есть свои ключевые слова. Формат запроса будет такой:
SELECT * FROM netflix
ORDER BY title DESC
- ORDER BY — ключевое слово для сортировки вывода данных. - ASC — сортировка от меньшего к большему (применяется по умолчанию, если ничего не указать). - DESC — сортировка от большего к меньшему.
Группировка данных
Группировка может быть нужна, если мы хотим разделить все данные на логические наборы. Например, узнать, для каких стран режиссеры снимали фильмы по данным нашей БД. - GROUP BY — ключевое слово для группировки данных.
SELECT director FROM netflix
GROUP BY director
Обратите внимание: если вы указываете колонку в блоке SELECT, она должна быть и в GROUP BY.
Агрегирующие функции
Агрегирующие функции позволяют нам проводить простые вычисления на имеющихся данных. Все их понимают интуитивно, и, руководствуясь здравым смыслом, вы легко их освоите.
COUNT(<название поля>)
Считает количество не null строк в поле (то есть вернет количество записей конкретного столбца за исключением записей null).
Помним, что **null** — это специальное слово, которым в SQL обозначают пустые значения и используют, когда значение в каком-то поле не указано. Например, если вы отказались заполнять поле «О себе» на каком-нибудь форуме, в базу данных будет передано значение **null** в поле **about_myself**, где должен содержаться текст «О себе».
SUM(<название поля>)
Функция с интригующим названием. Она суммирует значения числового поля.
Пример
AVG(<поле>)
Считает среднее (AVG от англ. average — среднее). Это именно то, что мы в быту называем средним, а в статистике это именуется средним арифметическим.
Иными словами, сумма, деленная на количество.
С функциями SUM и AVG могут использоваться только числовые поля. С функциями COUNT, MAX и MIN могут использоваться как числовые, так и символьные поля.
MAX(<поле>),
MIN(<поле>)
Находят максимальное и минимальное значения в поле.
Поле не обязательно должно содержать числовые данные.
С текстовыми данными и датами функции тоже работают. Напомним, что строки будут отсортированы в алфавитном порядке, как в словаре, и будет выбрано либо самое первое (MIN), либо самое последнее (MAX) значение. Проводить вычисления можно как на всей таблице, так и используя группировку.
SELECT COUNT(*) FROM netflix # этот запрос выведет нам общее количество тайтлов в базе
SELECT director, COUNT(*) FROM netflix # этот запрос позволит посчитать количество
GROUP BY director # тайтлов у каждого режиссера
Оператор HAVING
Иногда нам нужно сделать фильтрацию по результату агрегирующей функции. Например, узнать обо всех режиссерах, которые сняли больше 5 фильмов. Почему нельзя условие задать в блоке WHERE? Всё дело в последовательности выполнения запроса.
SELECT director, COUNT(*) FROM netflix
WHERE type = 'Movie' # фильтруем так, чтоб в выборку попали только фильмы
GROUP BY director # группируем по режиссерам
HAVING COUNT(*) > 5 # выводим только тех, у кого больше 5 тайтлов
Порядок выполнения SQL-операций
SQL — декларативный язык. Это значит, что наш запрос описывает ожидаемый результат, а не последовательность его получения. Внутри БД действия выполняются в следующем порядке:
1. FROM — выбираем таблицу, из которой будем получать данные. 2. WHERE — фильтруем строки по условию. 3. GROUP BY — агрегируем данные. 4. HAVING — фильтруем агрегированные данные. 5. SELECT — возвращаем набор данных (например, получившуюся таблицу). 6. ORDER BY — сортируем ее при необходимости. Получается, если взять наш запрос:
SELECT director, COUNT(*) as titles_number # 5. Вернули таблицу
FROM netflix # 1. Выбрали таблицу netflix
WHERE type = 'Movie' # 2. Оставили в таблице только фильмы
GROUP BY director # 3. Сделали группировку по режиссерам
HAVING COUNT(*) > 5 # 4. Оставили только тех, у кого больше 5 фильмов
ORDER BY titles_number # 6. Отсортировали таблицу
Оглавление
1. Определяем структуру таблицы и ее основные поля
4. Добавляем ограничения на ввод данных
Как изменить существующую таблицу
Редактировать данные через Python
Создаем локальную БД
База создается на локальном диске при первом к ней обращении.
con = sqlite3.connect('nameof.db')
Создаем таблицы внутри БД
Для создания таблицы используется ключевое слово CREATE. Лучше всего писать запрос по шагам.
1. Определяем структуру таблицы и ее основные поля
CREATE TABLE books
(Id,
Name,
Author,
Description,
Genre,
Publication_date,
Pages_number)
2. Определяем тип столбцов
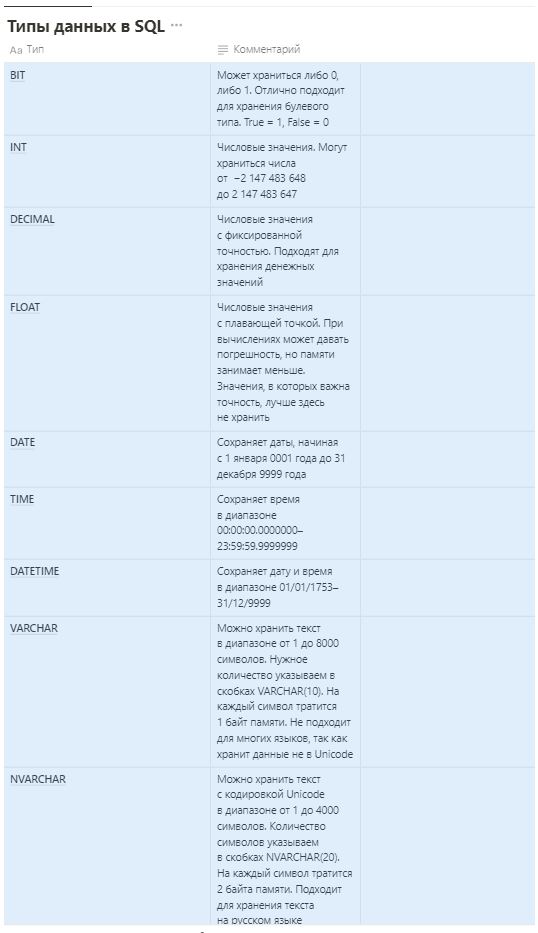
Список основных типов вы можете посмотреть в таблице.
Когда мы выбрали тип данных для каждого столбца, наш запрос будет выглядеть так:
CREATE TABLE books
(Name NVARCHAR(50),
Author NVARCHAR(100),
Description NVARCHAR(500),
Genre NVARCHAR(30),
Publication_date DATE,
Pages_number INT
)
3. Добавляем первичный ключ
Первичный ключ — это столбец, который уникально идентифицирует строку в таблице. Можно создать столбец, который мы будем заполнять самостоятельно, а можно сделать так, чтобы он заполнялся автоматически с помощью ключевого слова AUTO_INCREMENT.
CREATE TABLE books
(Id INT PRIMARY KEY AUTO_INCREMENT,
Title NVARCHAR(50),
Author NVARCHAR(100),
Description NVARCHAR(500),
Genre NVARCHAR(30),
Publication_date DATE,
Pages_number INT
)
4. Добавляем ограничения на ввод данных
Добавляем ограничения на ввод данных с помощью ключевого слова `CONSTRAIN`. CONSTRAINT column DEFAULT 'Default' — эта конструкция поможет создать значение по умолчанию, если мы будем заносить пустые данные. CONSTRAINT column CHECK condition — эта конструкция установит проверку при вводе данных и не позволит ввести строки, не соответствующие условию. Финальный запрос будет выглядеть так:
CREATE TABLE books
(Id INT PRIMARY KEY,
Title NVARCHAR(50) NOT NULL,
Author NVARCHAR(100),
Description NVARCHAR(500),
Genre NVARCHAR(30)
CONSTRAINT DF_genre DEFAULT 'Undefined',
Publication_date DATE,
Pages_number INT
CONSTRAINT CK_page_number CHECK (Pages_number > 0)
)
Как изменить существующую таблицу
ALTER TABLE — ключевое слово для изменения существующей таблицы. ADD columnname INT — добавляем колонку. ALTER COLUMN columnname VARCHAR — изменяем тип колонки.
ALTER TABLE books
ADD Rating INT
DROP COLUMN columnname — удаляем колонку.
ALTER TABLE books
DROP COLUMN Rating
Как удалить таблицу
Если мы поняли, что таблица больше точно не нужна, или мы ошиблись в проектировании и хотим всё переделать, можно удалить таблицу. DROP TABLE — ключевое слово для удаления таблиц.
DROP TABLE books
Редактировать данные через Python
Если нам важно редактировать данные именно через код внутри Python, следует немного изменить наш код:
con = sqlite3.connect("#name_of_bd")
cur = con.cursor()
sqlite_query = "ЗДЕСЬ БУДЕТ ТЕКСТ ВАШЕГО ЗАПРОСА"
cur.execute(sqlite_query)
cur.fetchall()
con.commit() #Не просто закрываем соединение, а коммитим все внесенные изменения
Как добавить данные
`INSERT` — ключевое слово для добавления данных. Данные мы можем добавить разными способами. Если мы заносим данные, которых пока нет в нашей БД, можно использовать конструкцию (если хотим вставить данные в часть колонок):
Или, если нужно вставить данные во все колонки таблицы:
INSERT INTO books (column1, column2)
VALUES (value1, value2)
Если у нас эти данные есть в других таблицах (или можно сделать выборку с помощью SELECT так, чтобы сформировать нужный датасет), можно использовать такой формат запроса:
INSERT INTO books
VALUES (value1, value2)
INSERT INTO books1
SELECT * FROM books
WHERE condition
Как изменить данные
UPDATE — ключевое слово для изменения данных. Можно изменить как все данные, так и конкретные строки, которые можно найти по любому условию.
UPDATE books
SET column1 = 'value'
WHERE column2 > 3
Как удалить данные
DELETE FROM — ключевое слово для удаления данных. По аналогии с UPDATE можно удалить как все данные, так и конкретные строки, которые можно найти по любому условию.
DELETE FROM books
WHERE Id = 3
Оглавление
Как связать таблицы
В хорошо спроектированных приложениях данные хранятся в нескольких таблицах. Например, создавая фильмотеку, мы заводим отдельную таблицу для фильмов, режиссеров, наград и жанров. Почему так делают?
- Такие таблицы меньше, с ними удобнее работать - Информация в таких табицах не дублируется - Можно менять одни таблицы независимо от других
Когда отдельные таблицы заведены, вместо имени, фото и страны режиссера мы ставим , например 1 или 2. Это означает, что теперь информацию нужно искать в таблице режиссеров в строке 2.
На практике это приводит вот к чему: чтобы вывести карточку фильма с полной информацией (название, описание, режиссер, награды, жанры), нам нужно одним запросом получить данные из нескольких таблиц.
Один к одному
Тип встречается нечасто, выглядит как разделение одной таблицы на две части. Может использоваться для разделения на логические сущности. Например, один паспорт у одного человека.
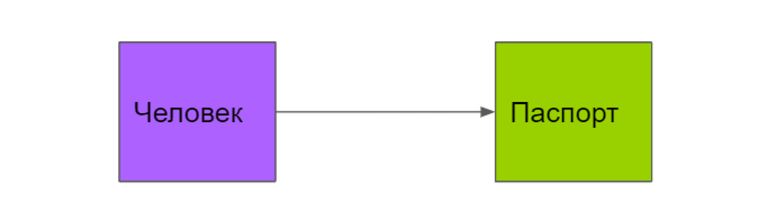
Паспорт принадлежит конкретному человеку. У человека может быть только один паспорт.
Один ко многим
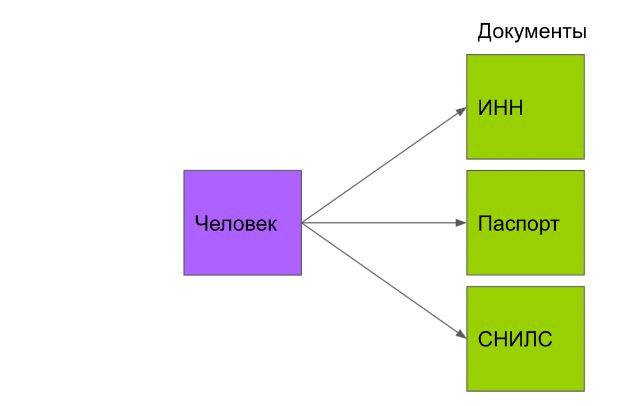
Все документы принадлежат одному человеку. Человек может иметь много документов
Многие ко многим
Подходит для создания связей между объектами, если каждый из них может иметь несколько строк в другой таблице.
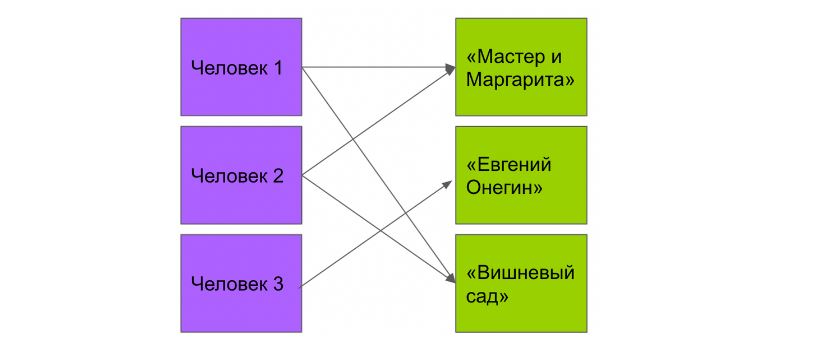
Человек может читать несколько книг. Книгу могут читать несколько человек.
Внешний ключ
**Внешний ключ** — это столбец в БД, который соответствует первичному ключу в другой таблице. Он позволяет: - связать таблицы между собой (обычно устанавливается в подчиненной таблице), - указать поведение при удалении или изменении строки в главной таблице.
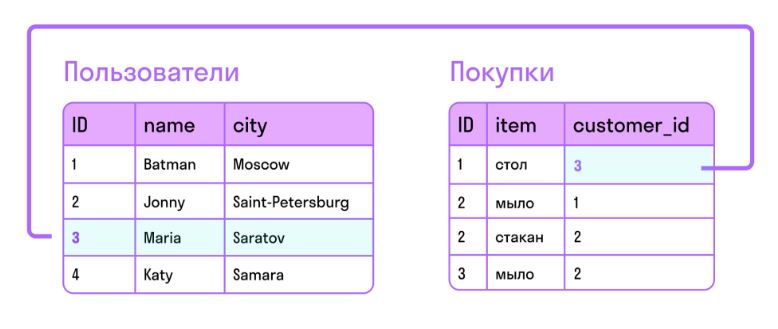
FOREIGN KEY — ключевое слово для создания внешнего ключа. Устанавливается при создании таблицы.
ON DELETE — ключевое слово для указания действий при удалении строки в главной таблице. ON UPDATE — ключевое слово для указания действий при изменении строки в главной таблице.
CREATE TABLE books(
Id INT PRIMARY KEY AUTO_INCREMENT,
AuthorId INT,
FOREIGN KEY (AuthorId) REFERENCES Authors (Id)
)
Можно указать различные варианты действий. Они одинаковые для обоих ключевых слов: CASCADE — автоматически удаляет/изменяет строки в зависимой таблице при изменении/удалении строк в главной.
SET NULL — устанавливает значение NULL для столбца внешнего ключа в зависимой таблице при изменении/удалении строк в главной.
RESTRICT — отклоняет изменение/удаление строк в главной таблице, если есть связанные строки в зависимой.
SET DEFAULT — при удалении связанной строки из главной таблицы устанавливает в зависимой вместо внешнего ключа то значение, которое мы указали при использовании CONSTRAINT(см. шпаргалку к уроку 15.1).
Полный вид запроса будет выглядеть так:
CREATE TABLE Books
(
Id INT PRIMARY KEY,
Title VARCHAR,
AuthorId,
FOREIGN KEY (AuthorId) REFERENCES Authors (Id) ON DELETE CASCADE
);
Как объединить таблицы
JOIN — специальная операция для объединения данных из двух таблиц. Есть разные виды JOIN в зависимости от тех задач, которые перед вами стоят. Общий код запроса будет выглядеть примерно одинаково.
1. Выбираем данные с помощью SELECT. 2. Можем указать звездочку или те столбцы из обеих таблиц, которые нам нужны. 3. Используем ключевое слово JOIN (или другой подходящий вариант из четырех вариантов JOIN, представленных ниже). 4. Определяем, по какому столбцу мы будем соединять.
SELECT * FROM movies
JOIN directors ON movies.DirectorId = directors.Id
Чтобы было нагляднее, представим, что у нас есть две таблицы.
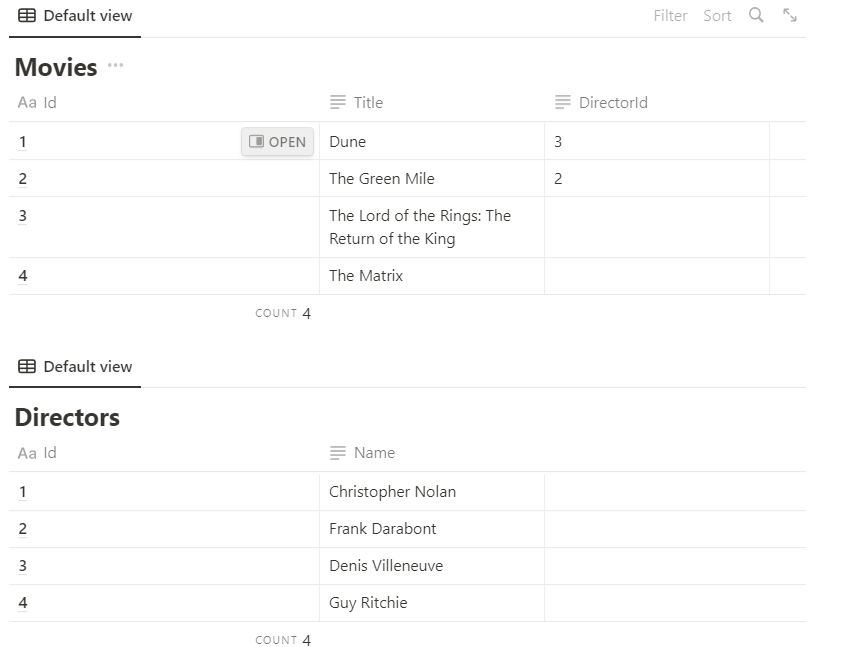
1. INNER JOIN
Подходит, если нам нужно найти только пересечение двух таблиц. Графически можно изобразить так:
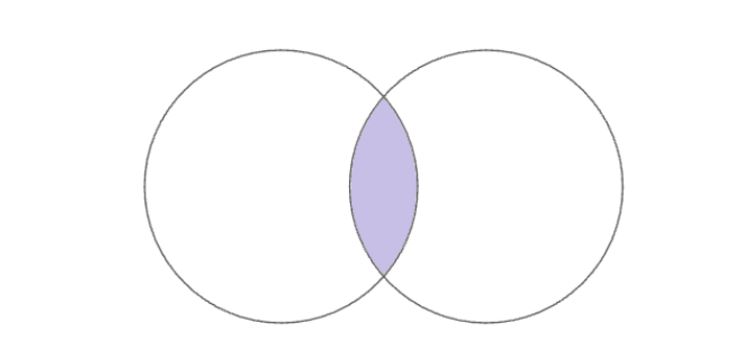
Разберем на примере.
SELECT * FROM movies
INNER JOIN directors ON movies.DirectorId = directors.Id

В наш запрос попали только те строки, для которых есть значения в обеих таблицах.
2. LEFT JOIN
Подходит, если нам нужно найти все значения из первой таблицы и их пересечения со второй. Графически можно изобразить так:
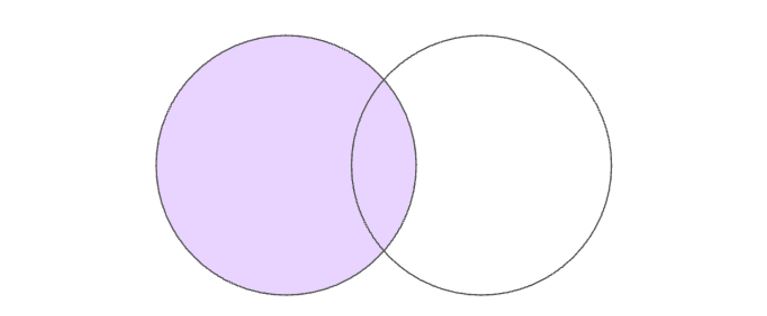
Разберем на примере.
SELECT * FROM movies
LEFT JOIN directors ON movies.DirectorId = directors.Id
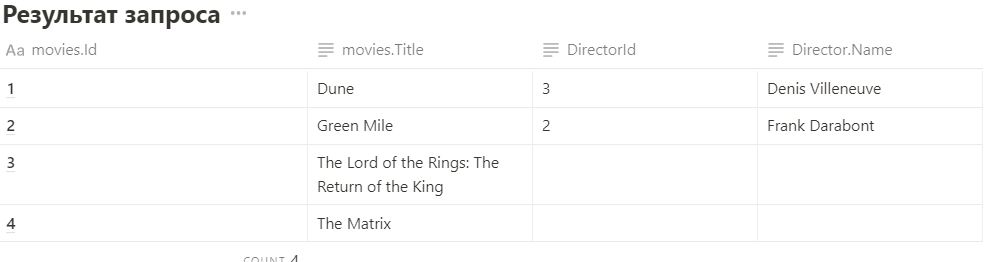
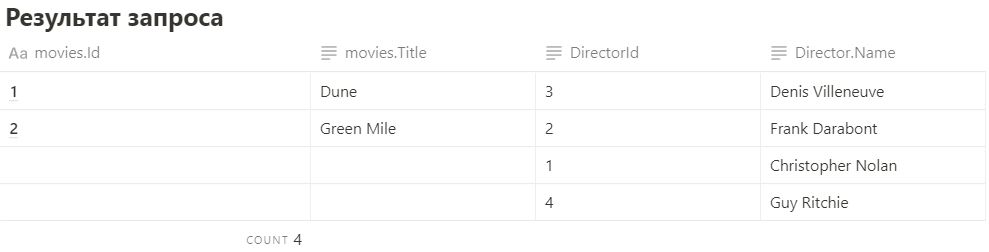
3. RIGHT JOIN
Подходит, если нам нужно найти все значения из второй таблицы и их пересечения с первой. Графически можно изобразить так:
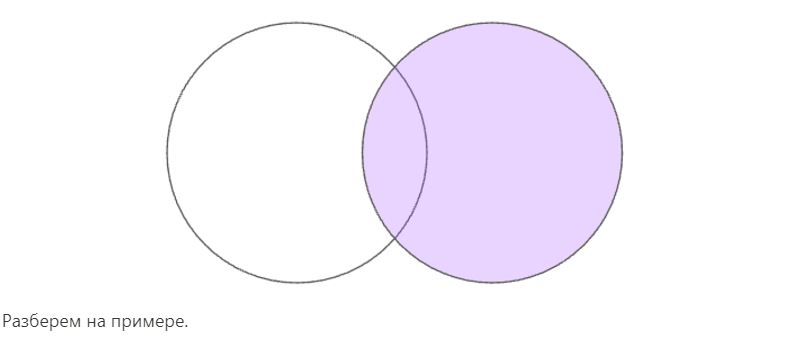
SELECT * FROM movies
RIGHT JOIN directors ON movies.DirectorId = directors.Id
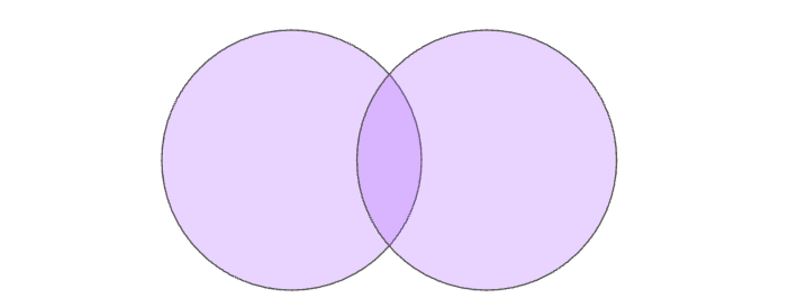
4. FULL JOIN
Подходит, если нам нужно найти все значения из первой и второй таблицы и их пересечения. Графически можно изобразить так:
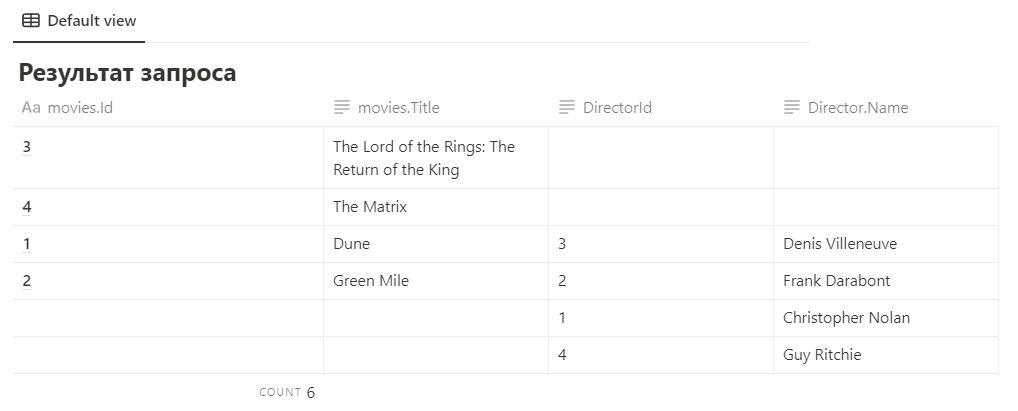
SELECT * FROM movies
OUTER JOIN directors ON movies.DirectorId = directors.Id
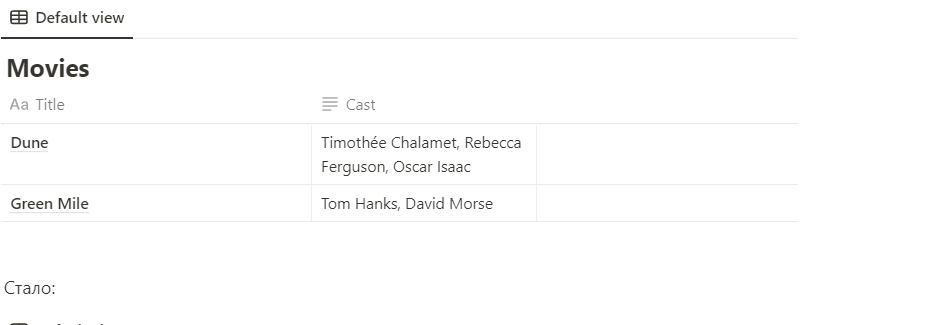
Что такое нормальная форма?
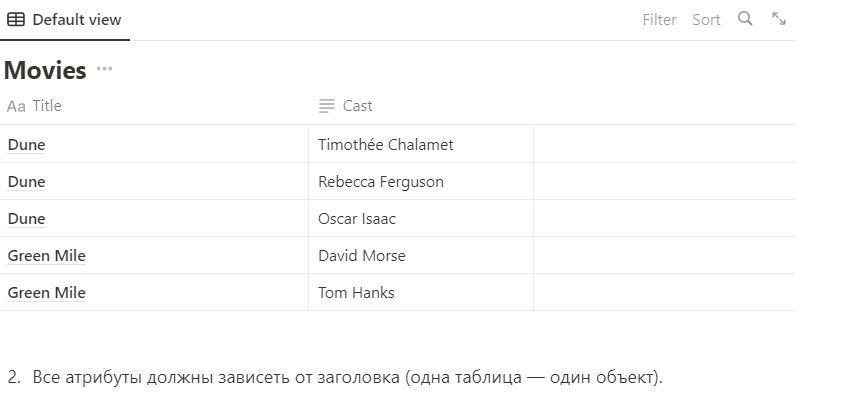
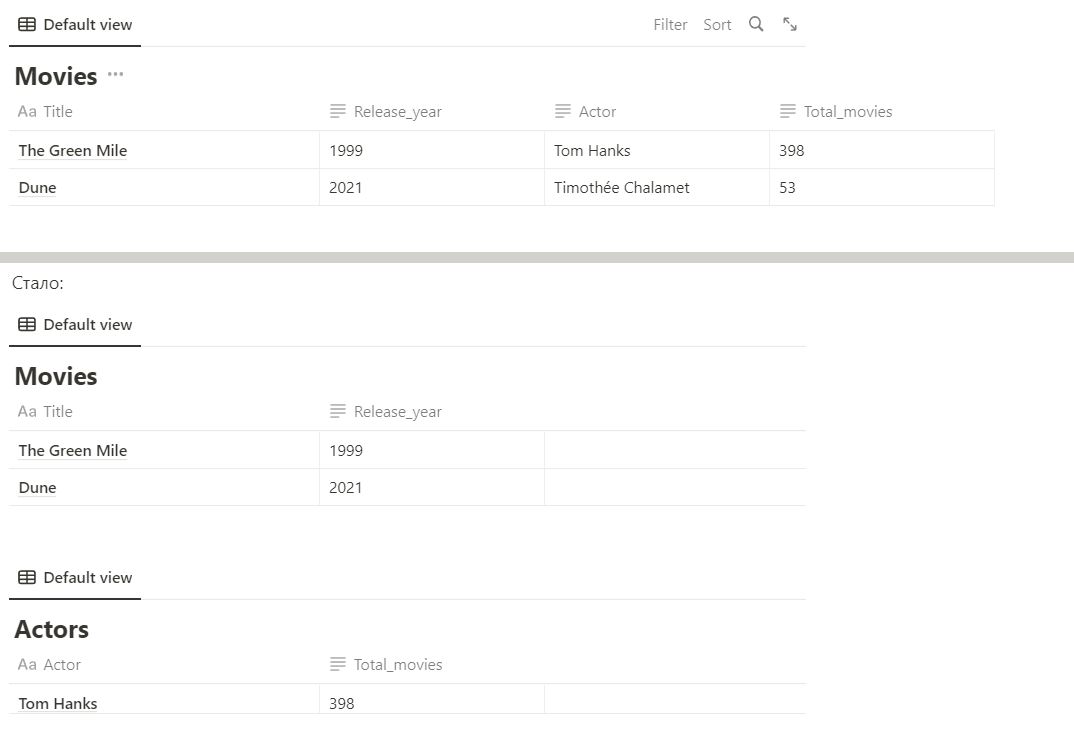
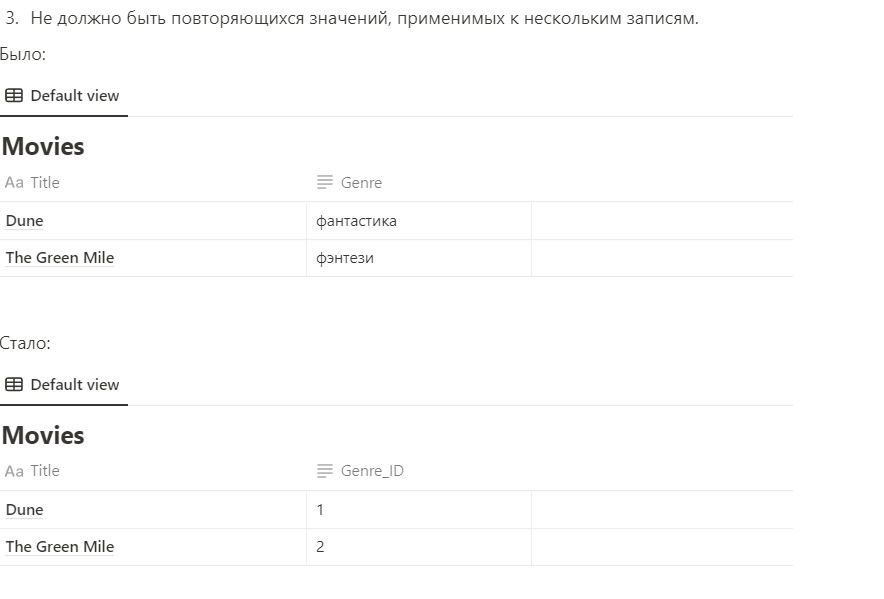
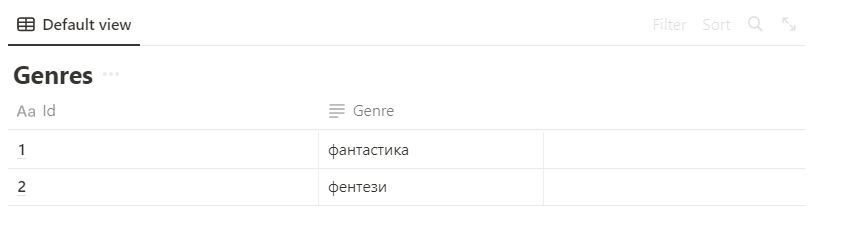
Нормальная форма — требования, которые должна выполнять БД, чтобы свести к минимуму ошибки в результатах выборки или изменения данных. 1. Не должно быть наборов значений в одной строке. Было:
Оглавление
Как установить SQLAlchemy и Flask-SQLAlchemy?
Как создать таблицы по готовым моделям?
Как получить все сущности из БД?
Как настроить Flask и SQLAlchemy?
Преимущества ORM
- Не требуется ручного маппинга. - Не надо писать запросы. - Безопасность. - Абстрагирование от реализации DBMS.
Как установить SQLAlchemy и Flask-SQLAlchemy?
pip3 install flask flask-sqlalchemy sqlalchemy
Connection String для SQLite
'sqlite:////tmp/sqlite3.db'
В памяти:
'sqlite:///:memory:'
Типы полей
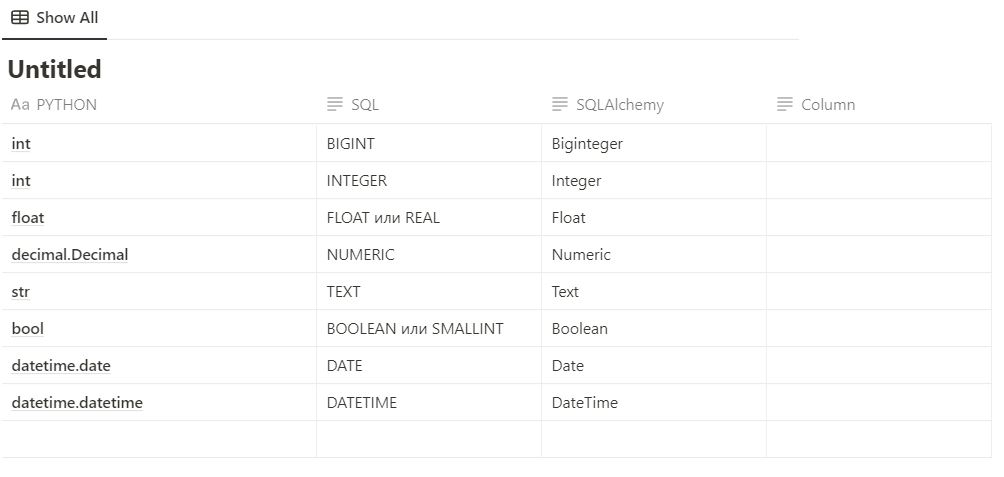
Пример модели SQLAlchemy:
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy(app)
class User(db.Model):
__tablename__ = 'user'
id = db.Column(db.Integer, primary_key=True)
first_name = db.Column(db.String(100))
last_name = db.Column(db.String)
age = db.Column(db.Integer)
email = db.Column(db.String(100))
role = db.Column(db.String(100))
phone = db.Column(db.String(100))
Как создать таблицы по готовым моделям?
Сначала создайте модели, потом вызовите метод:
db.create_all()
А если надо удалить все таблицы вместе с данными, то:
db.drop_all()
Как добавить данные в БД?
max = User(id=3, name='max', age=32)
db.session.add(max)
db.session.commit()
Как получить все сущности из БД?
users = db.session.query(User).all()
Как настроить Flask и SQLAlchemy?
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///:memory:'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app)
Оглавление
Как сделать две таблицы связанными «один ко многим»?
Как создать связанные сущности одним запросом в БД?
Как сделать ограничение NOT NULL?
Как сделать ограничение UNIQUE?
Как сделать проверку, чтобы нельзя было вставить строки с полем age < 18?
Как сделать ограничение связанной таблицы?
Как получить всех пользователей старше 18 лет?
Как получить всех пользователей, чье имя начинается на "Po"?
Как отсортировать пользователей по полю по возрастанию?
Как написать inner join связанных таблиц User и Group?
Как написать outer join связанных таблиц User и Group?
Связи
Как сделать две таблицы связанными «один ко многим»?
class User(db.Model):
__tablename__ = 'user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(100))
age = db.Column(db.Integer)
group_id = db.Column(db.Integer, db.ForeignKey('group.id'))
group = db.relationship("Group")
class Group(db.Model):
__tablename__ = "group"
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(100))
users = db.relationship("User")
Таблица User ссылается на таблицу Group, в одной группе может быть много пользователей.
Как создать связанные сущности одним запросом в БД?
usr200 = User(id=200, name='michael', age=30)
grp200 = Group(id=200, name="Test Group 200", users=[usr200])
db.session.add(grp200)
db.session.commit()
Ограничение
Какое ограничение для модели является обязательным?
class User(db.Model):
__tablename__ = 'user'
id = db.Column(db.Integer, primary_key=True)
Как сделать ограничение NOT NULL?
class User(db.Model):
__tablename__ = 'user'
...
passport_number = db.Column(db.String(3), nullable=False)
Как сделать ограничение UNIQUE?
class User(db.Model):
__tablename__ = 'user'
...
passport_number = db.Column(db.String(3), unique=True)
Как сделать проверку, чтобы нельзя было вставить строки с полем age < 18?
class User(db.Model):
__tablename__ = 'user'
...
age = db.Column(db.Integer, db.CheckConstraint("age > 18"))
Как сделать ограничение связанной таблицы?
class User(db.Model):
__tablename__ = 'user'
...
group_id = db.Column(db.Integer, db.ForeignKey('group.id'))
Фильтрация
Как получить всех пользователей старше 18 лет?
users = db.session.query(User).filter(User.age > 18).all()
Как получить всех пользователей, чье имя начинается на "Po"?
users = db.session.query(User).filter(User.name.like("Po%")).all()
Сортировка
Как отсортировать пользователей по полю по возрастанию?
db.session.query(User).filter(User.name.ilike("ma%")).order_by(User.age).all()
А по убыванию?
from sqlalchemy import desc
db.session.query(User).filter(User.name.ilike("ma%")).order_by(desc(User.age)).all()
Как написать inner join связанных таблиц User и Group?
db.session.query(User.id, User.name, Group.name.label("grp_name")).join(Group).all()
Как написать outer join связанных таблиц User и Group?
db.session.query(
User.name.label("username"),
Group.name.label("groupname"),
).outerjoin(Group).all()
Limit & Offset
Как написать запрос с limit?
db.session.query(User).limit(2).all()
Как написать запрос с offset?
db.session.query(User).limit(2).offset(2).all()